Registro de Datos de Fragmentación de Índices de Bases de Datos SQL de Azure en Azure Log Analytics
Tabla de Contenidos
- Registro de Datos de Fragmentación de Índices de Bases de Datos SQL de Azure en Azure Log Analytics
- Introducción a la Fragmentación de Índices en Bases de Datos SQL de Azure
- Mezcla de Roles: datos de fragmentación del Administrador de SQL y datos KQL para el Administrador de Azure
- Uso de DCR y DCE para recopilar los datos
- Espacio de Trabajo de Log Analytics
- Tabla personalizada de Log Analytics
- Data Collection Endpoints (DCE)
- Data Collection Rules (DCR)
- Permisos
- Ingestar datos en Log Analytics
- Exposición de datos en Workbooks
- Conclusiones
- Autor
Introducción a la Fragmentación de Índices en Bases de Datos SQL de Azure
La fragmentación de índices ocurre cuando los datos dentro de un índice se almacenan de manera ineficiente, lo que lleva a una fragmentación lógica y física. La fragmentación lógica se refiere a la disposición desordenada de las páginas del índice, mientras que la fragmentación física implica datos dispersos a lo largo del disco o medio de almacenamiento. Ambos tipos de fragmentación aumentan las operaciones de lectura necesarias para recuperar datos, resultando en un rendimiento más lento de las consultas. A medida que la fragmentación se acumula, se vuelve esencial monitorear y gestionar la fragmentación para mantener un rendimiento óptimo de la base de datos, especialmente en entornos con altos volúmenes de operaciones de datos.
Los entornos SQL PaaS (Plataforma como Servicio), como Azure SQL Database, simplifican la gestión de bases de datos automatizando tareas como escalado, seguridad y copias de seguridad. Esto los convierte en una opción preferida para aplicaciones dinámicas y de alto volumen. Sin embargo, con inserciones, actualizaciones y eliminaciones de datos frecuentes, las bases de datos SQL PaaS son propensas a la fragmentación de índices. A diferencia de las bases de datos locales, donde los administradores pueden abordar la fragmentación manualmente, los entornos PaaS se benefician de soluciones de Monitorización automatizadas debido a su escala y cargas de trabajo dinámicas. Siga el enlace para obtener más información sobre las características de gestión de Azure SQL Database.
Mezcla de Roles: datos de fragmentación del Administrador de SQL y datos KQL para el Administrador de Azure
En esta publicación, presentamos un método para monitorear la fragmentación de índices en SQL PaaS utilizando Data Collection Rules (DCR) y Data Collection Endpoints (DCE) de Azure. Con estas características, las métricas de fragmentación se pueden recopilar regularmente y enviar a Log Analytics. Luego, los datos se pueden leer fácilmente utilizando Kusto Query Language (KQL). Este método permite exponer y consultar los datos utilizando Azure Workbooks. Es una gran mezcla de datos específicos del producto (como el análisis de fragmentación de índices de SQL Server) y herramientas estándar de Azure Monitoring como Log Analytics, DCE, DCR, KQL y Workbooks. Para más información sobre la configuración de DCR y DCE, consulte este enlace: Reglas de Recopilación de Datos de Azure Monitor.
Esta publicación mezcla dos mundos de Administradores: Administrador de Azure y Administrador de SQL Server. Como administradores, estos son los tipos de consultas involucradas en esta publicación:
- SQL Server DBA query:
SELECT
@@SERVERNAME AS server_name,
db_name() AS database_name,
s.name AS schema_name,
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ips.index_type_desc,
cast(ips.avg_fragmentation_in_percent as decimal(10,2)) avg_fragmentation_in_percent,
ips.page_count,
getdate() as TimeGenerated
FROM
sys.dm_db_partition_stats ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id AND ps.index_id = i.index_id
CROSS APPLY sys.dm_db_index_physical_stats(DB_ID(), ps.object_id, ps.index_id, NULL, 'LIMITED') ips
INNER JOIN sys.objects o ON ps.object_id = o.object_id
INNER JOIN sys.schemas s ON o.schema_id = s.schema_id
WHERE ips.avg_fragmentation_in_percent > 50
ORDER BY ips.avg_fragmentation_in_percent DESC;
- Azure Admin KQL query:
Custom-TablesFragmentation_CL
| project
server_name, schema_name, table_name, index_name, index_type_desc,
avg_fragmentation_in_percent, page_count,
Res_TenantId, Res_SubscriptionId, Res_ResourceId, TimeGenerated
Estos son los recursos que deben crearse:
- Espacio de trabajo de Log Analytics
- Tabla personalizada para almacenar los datos en Log Analytics
- Punto de Recopilación de Datos para conectar con el Espacio de Trabajo de Log Analytics
- Regla de Recopilación de Datos que gobierna el esquema de datos y “conecta” el Punto de Recopilación con la tabla de Log Analytics
Uso de DCR y DCE para recopilar los datos
Para recopilar eficientemente los datos de fragmentación de índices de una base de datos SQL de Azure, utilizamos Data Collection Endpoints (DCE) y Data Collection Rules (DCR), ambos parte de Azure Monitor. Estas herramientas definen qué datos recopilar y dónde enviarlos, permitiendo una recolección y análisis eficiente de las métricas de fragmentación.
Para insertar los datos en Azure Log Analytics, utilizamos llamadas API para la ingestión directa en Azure Log Analytics. Este enlace muestra los detalles.
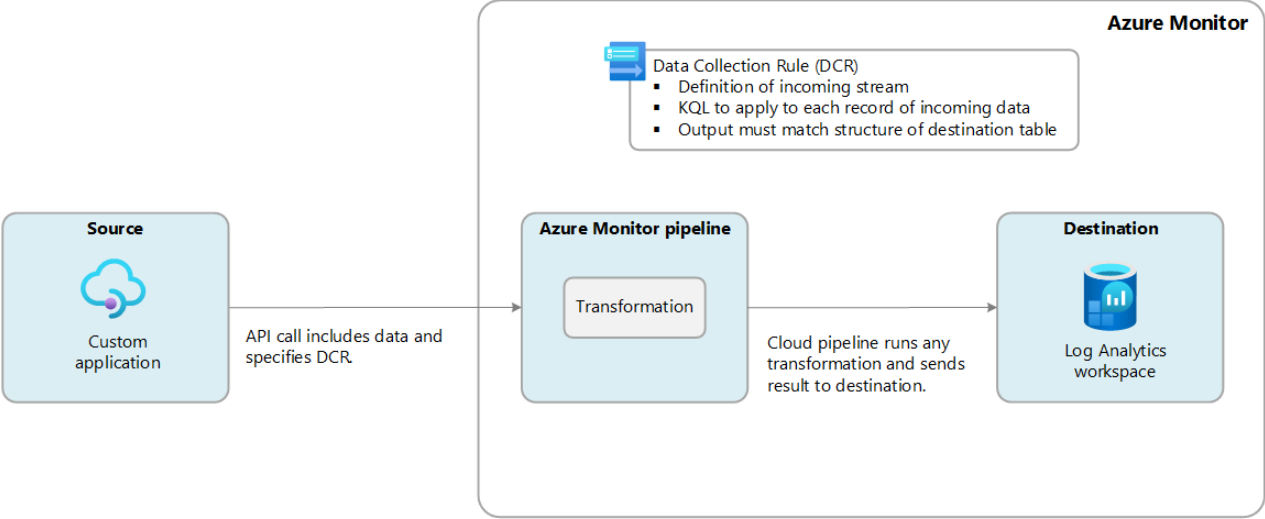
Estos son los detalles de nuestro caso:
- La fuente (Aplicación Personalizada) es un
Azure Runbook, que se activa cada 6 horas. - No hay necesidad de transformar los datos: Los datos que ingresan en la canalización se ingieren en
Azure Log Analytics.
Para ejecutar esta ingestión de datos, es necesario configurar:
- Un Espacio de Trabajo de Log Analytics
- Una tabla personalizada en el Espacio de Trabajo de Log Analytics
- Un Punto de Recopilación de Datos
- Una Regla de Recopilación de Datos
Nota. Recomendamos usar service principals con estos permisos:
Publicador de Métricas de Monitorizaciónen el Espacio de Trabajo de Log Analytics, DCE y DCR.Lector de Monitorizaciónen el Espacio de Trabajo de Log Analytics, DCE y DCR.- Permisos suficientes para acceder a las DMVs relevantes Permisos de SQL Server
Espacio de Trabajo de Log Analytics
El Espacio de Trabajo de Log Analytics es un recurso poderoso dentro de Azure Monitor que permite a las organizaciones recopilar, analizar y visualizar datos de registros y rendimiento de diversas fuentes. Al centralizar el Monitorización de diferentes aplicaciones y servicios, los usuarios pueden obtener valiosos conocimientos sobre la salud del sistema, patrones de uso y posibles problemas. Este espacio de trabajo permite la retención de datos, consultas con Kusto Query Language (KQL) y la integración de varios servicios de Azure para una mayor capacidad de observación.
This is the code to create the Log Analytics Workspace:
# Create the Log Analytics Workspace
$subscriptionId = "your_subscription_GUID"
$workspaceName = "ws-loganalytics-dc"
New-AzOperationalInsightsWorkspace -ResourceGroupName $resourceGroupName `
-PublicNetworkAccessForIngestion "enabled" `
-Name $workspaceName `
-Location $location `
-Sku Standard
Tabla personalizada de Log Analytics
Después de crear el Espacio de Trabajo de Log Analytics, es necesario crear la tabla personalizada. Es excelente ajustarse a un esquema. Todo estará más bajo control. Si desea crearla desde el portal, siga este enlace. Si prefiere el código de PowerShell, este sería un buen patrón a seguir:
$subscriptionId = "your_subscription_GUID"
$resourceGroupName = "rg-erincon01"
$workspaceName = "ws-loganalytics-dc"
$tableName = "Custom-TablesFragmentation_CL"
# url for post
$url = "https://management.azure.com/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.OperationalInsights/workspaces/$workspaceName/tables/$tableName?api-version=2021-12-01-preview"
# body for post
$body = @{
properties = @{
schema = @{
name = $tableName
columns = @(
@{ name = "server_name"; type = "string" },
@{ name = "schema_name"; type = "string" },
@{ name = "table_name"; type = "string" },
@{ name = "index_name"; type = "string" },
...
@{ name = "Res_TenantId"; type = "string" }
@{ name = "Res_SubscriptionId"; type = "string" }
@{ name = "Res_ResourceGroup"; type = "string" }
@{ name = "Res_ResourceId"; type = "string" }
)
}
retentionInDays = 30
}
} | ConvertTo-Json -Depth 5
# access token
$token = (Get-AzAccessToken -ResourceUrl "https://management.azure.com").Token
# PUT request
Invoke-RestMethod -Uri $url -Method Put -Headers @{ Authorization = "Bearer $token" } -Body $body -ContentType "application/json"
Note que hemos añadido algunas columnas que comienzan con “Res_%”. Queremos facilitar a los desarrolladores de workbooks “vincular” el recurso de Azure que está ingresando los datos.
Data Collection Endpoints (DCE)
Los Data Collection Endpoints (DCE) definen el destino al que se enviarán los datos recopilados. Los DCE actúan como un punto de entrega, dirigiendo los datos recopilados a una ubicación específica, como Log Analytics. En esta configuración, el DCE sirve como un puente que facilita el flujo de métricas de fragmentación de índices desde las bases de datos SQL PaaS a Log Analytics, permitiendo un Monitorización y análisis centralizados.
Un Data Collection Endpoints (DCE) puede ser utilizado en múltiples Data Collection Rules (DCRs), permitiendo la recopilación centralizada de datos de varias fuentes en un único destino como Log Analytics. Este enfoque simplifica la gestión de datos y optimiza el uso de recursos al reducir el número de puntos de recopilación necesarios, lo cual es especialmente beneficioso en entornos grandes. Al configurar múltiples DCRs para enviar datos al mismo DCE, puede monitorear eficientemente métricas similares, como la fragmentación de índices, desde diferentes bases de datos SQL PaaS o aplicaciones.
Para obtener una guía detallada sobre la configuración de DCE, consulte la documentación de DCE.
NOTA: Microsoft quiere hacer opcional DCE si no está utilizando Puntos de Conexión Privados. Sin embargo, no hemos podido configurar un DCE sin un DCE. Esta es una arquitectura de ejemplo utilizando DCE en un escenario de una sola región.
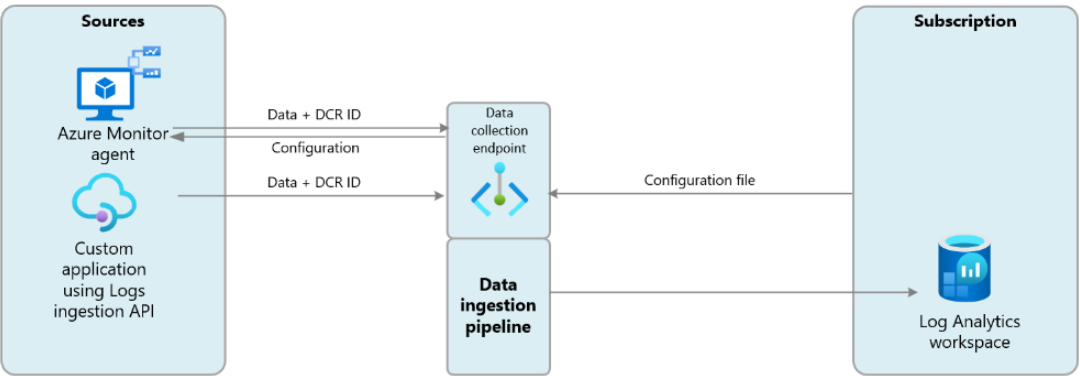
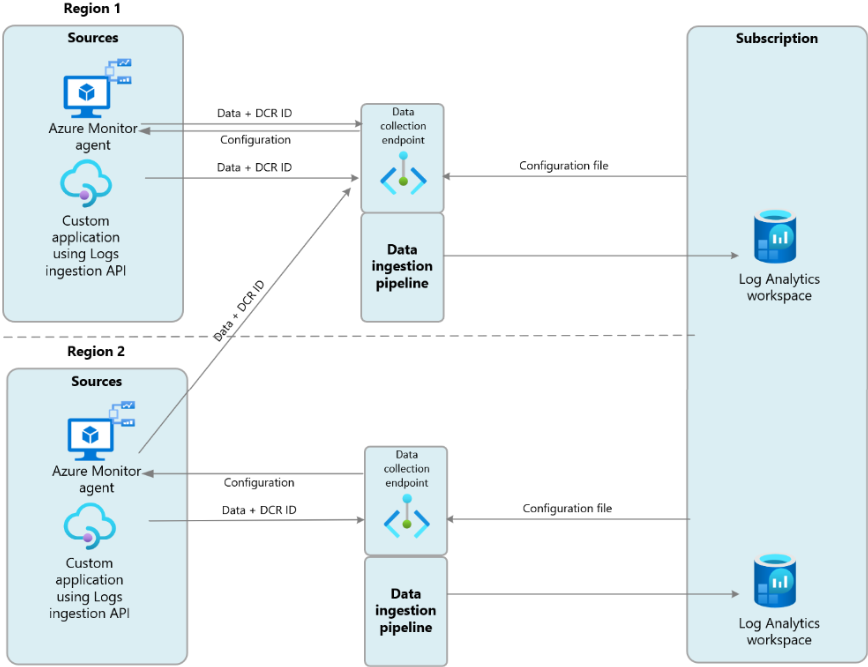
Los DCE son útiles en escenarios de múltiples regiones como muestra esta captura:
Este es el código de ejemplo para crear el Punto de Recopilación de Datos:
$resourceGroup="rg-erincon01"
$location="northeurope"
$dceName="sql-databases-dce"
# Create the Data Collection Endpoint
az monitor data-collection endpoint create `
--resource-group $resourceGroup `
--location $location `
--name $dceName `
--public-network-access "Enabled"
# list the dce to get the ImmutableId
az monitor data-collection endpoint list --resource-group $resourceGroup --output table
Data Collection Rules (DCR)
Una vez creado el DCE, debe crear las Data Collection Rules (DCR). Las DCR especifican los datos exactos a recopilar, como las métricas de fragmentación de índices, y los dirigen al DCE predefinido. Al configurar una DCR específicamente para las métricas de fragmentación de SQL PaaS, aseguramos un proceso de recopilación de datos consistente y estructurado, crucial para un Monitorización eficiente.
Una Data Collection Rules (DCR) en Azure puede configurarse para dirigirse a múltiples recursos específicos o diseñarse como una “plantilla reutilizable” que no requiere especificar un recurso en el momento de la creación. Esta configuración ofrece flexibilidad en la configuración y uso de DCR en diferentes entornos.
Para obtener más información sobre la configuración de DCR, consulte la documentación oficial sobre DCR.
Hay algunas consideraciones al construir DCR, para más detalles consulte este artículo de mejores prácticas.
Para nuestro escenario, este es el patrón del documento Json que hemos utilizado:
$dcrProperties = @{
location = $location
kind = "Direct"
properties = @{
streamDeclarations = @{
$streamName = @{
columns = @(
@{ name = "server_name"; type = "string" },
...
@{ name = "Res_TenantId"; type = "string" }
@{ name = "Res_SubscriptionId"; type = "string" }
@{ name = "Res_ResourceGroup"; type = "string" }
@{ name = "Res_ResourceId"; type = "string" }
)
}
}
destinations = @{
logAnalytics = @(
@{
workspaceResourceId = "worspaceId"
name = "LogAnalyticsDest"
}
)
}
dataFlows = @(
@{
streams = @($streamName)
destinations = @("LogAnalyticsDest")
transformKql = "kql query"
outputStream = $tableName
}
)
dataCollectionEndpointId = "dceId"
}
}
Para crear el DCR, tuvimos problemas con Azure CLI. Finalmente, decidimos usar la API REST para un mejor diagnóstico de problemas (manejo de errores de los métodos CLI de New-AzDataCollectionRule).
$jsonDcrProperties = $dcrProperties | ConvertTo-Json -Depth 20
# Llamada API-REST
$url = "https://management.azure.com/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Insights/dataCollectionRules/$dcrName?api-version=2023-03-11"
$token = (Get-AzAccessToken).Token
$response = Invoke-RestMethod -Uri $url -Method Put -Body $jsonDcrProperties -ContentType "application/json" -Headers @{Authorization = "Bearer $token"}
Permisos
Es necesario manejar correctamente los permisos. Siguiendo la regla de privilegio mínimo, si necesitas ingerir datos, se requiere el permiso Monitoring Metrics Publisher. Adicionalmente, para leer los registros, necesitarás el permiso Monitoring Reader. Recomendamos usar service principals. Usa este código como ejemplo/plantilla:
# monitoring permissions for service principal
$servicePrincipal_ObjectId = (Get-AzADServicePrincipal -ApplicationId $servicePrincipal).Id
$dceId = "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Insights/dataCollectionEndpoints/$dceName"
$dcrId = "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.Insights/dataCollectionRules/$dcrName"
$wksId = "/subscriptions/$subscriptionId/resourceGroups/$resourceGroupName/providers/Microsoft.OperationalInsights/workspaces/$workspaceName"
# publisher -- role assigment permissions to dce, dcr, and workspace
New-AzRoleAssignment -ObjectId $servicePrincipal_ObjectId -RoleDefinitionName "Monitoring Metrics Publisher" -Scope $dceId
New-AzRoleAssignment -ObjectId $servicePrincipal_ObjectId -RoleDefinitionName "Monitoring Metrics Publisher" -Scope $dcrId
New-AzRoleAssignment -ObjectId $servicePrincipal_ObjectId -RoleDefinitionName "Monitoring Metrics Publisher" -Scope $wksId
# reader -- role assigment permissions to dce, dcr, and workspace
New-AzRoleAssignment -ObjectId $servicePrincipal_ObjectId -RoleDefinitionName "Monitoring Reader" -Scope $dceId
New-AzRoleAssignment -ObjectId $servicePrincipal_ObjectId -RoleDefinitionName "Monitoring Reader" -Scope $dcrId
New-AzRoleAssignment -ObjectId $servicePrincipal_ObjectId -RoleDefinitionName "Monitoring Reader" -Scope $wksId
Ingestar datos en Log Analytics
Una vez que la infraestructura está configurada, está listo para ingerir datos en la tabla personalizada de Log Analytics. Este enlace incluye un ejemplo detallado. También puede usar este enlace para generar datos de muestra.
En nuestro caso, hemos construido esta arquitectura:
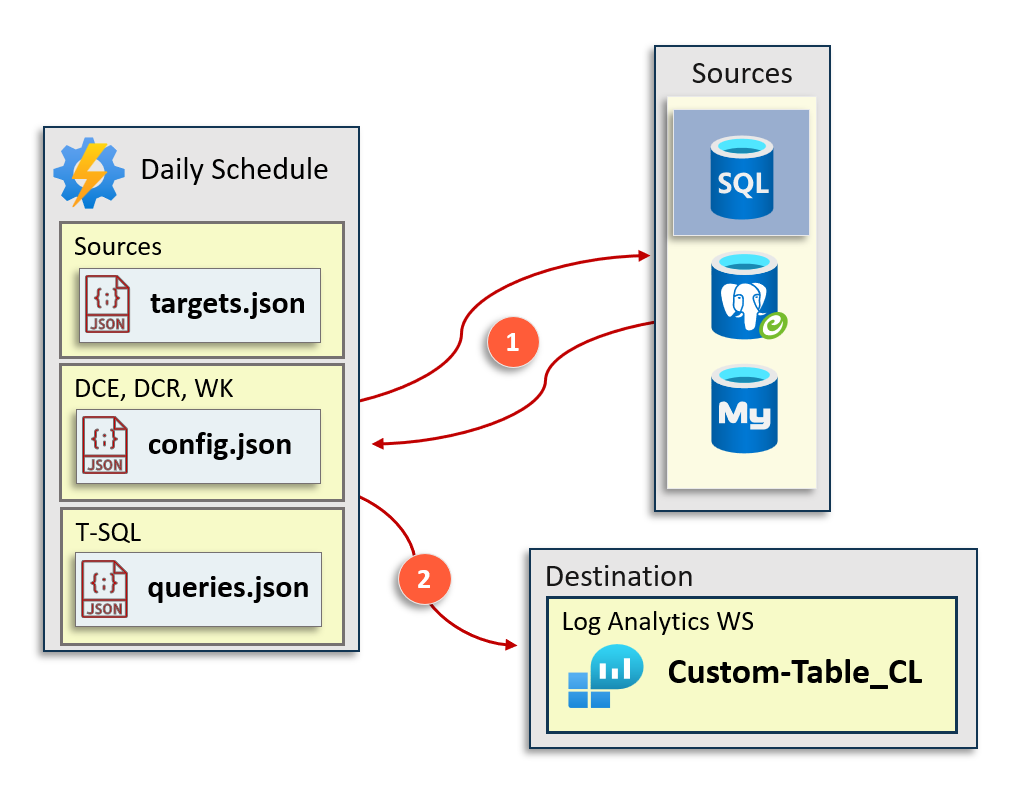
Donde tenemos estos archivos de configuración:
- logger.json que incluye el DCR, DCE y Log Analytics donde ingerir los datos.
- targets.json que incluye las fuentes de datos de SQL Server que queremos evaluar.
- queries.json que incluye los scripts de SQL Server para evaluar.
Para enviar los datos a Log Analytics, utilizamos nuevamente el enfoque de la API REST:
try {
$scope = "https://monitor.azure.com/.default"
$accessToken = Get-AccessToken -TenantId $tenantId -ClientId $clientId -ClientSecret $clientSecret -Scope $scope
$dateHeader = [DateTime]::UtcNow.ToString("R")
# Construir los encabezados HTTP
$headers = @{
"Authorization" = "Bearer $accessToken"
"Content-Type" = "application/json"
"x-ms-date" = $dateHeader
"Log-Type" = "VerneTechSQLServerMonitoring-$tableName"
}
$dceUri += "/dataCollectionRules/$dcrImmutableId/streams/Custom-$Table" + "?api-version=2023-01-01"
Write-Verbose "Request header: $($headers | Out-String)"
$response = Invoke-RestMethod -Uri $DceUri -Method POST -Body $jsonArray -Headers $headers -ErrorAction Stop
return $response
} catch {
# handling errors
Write-Error "Error al enviar datos a Log Analytics: $_"
}
Exposición de datos en Workbooks
Finalmente, los datos deben exponerse en un informe. Una vez que los datos están en Log Analytics, hay varias formas de construir informes.
Este es un ejemplo donde la tabla personalizada se expone en un Azure Workbook. 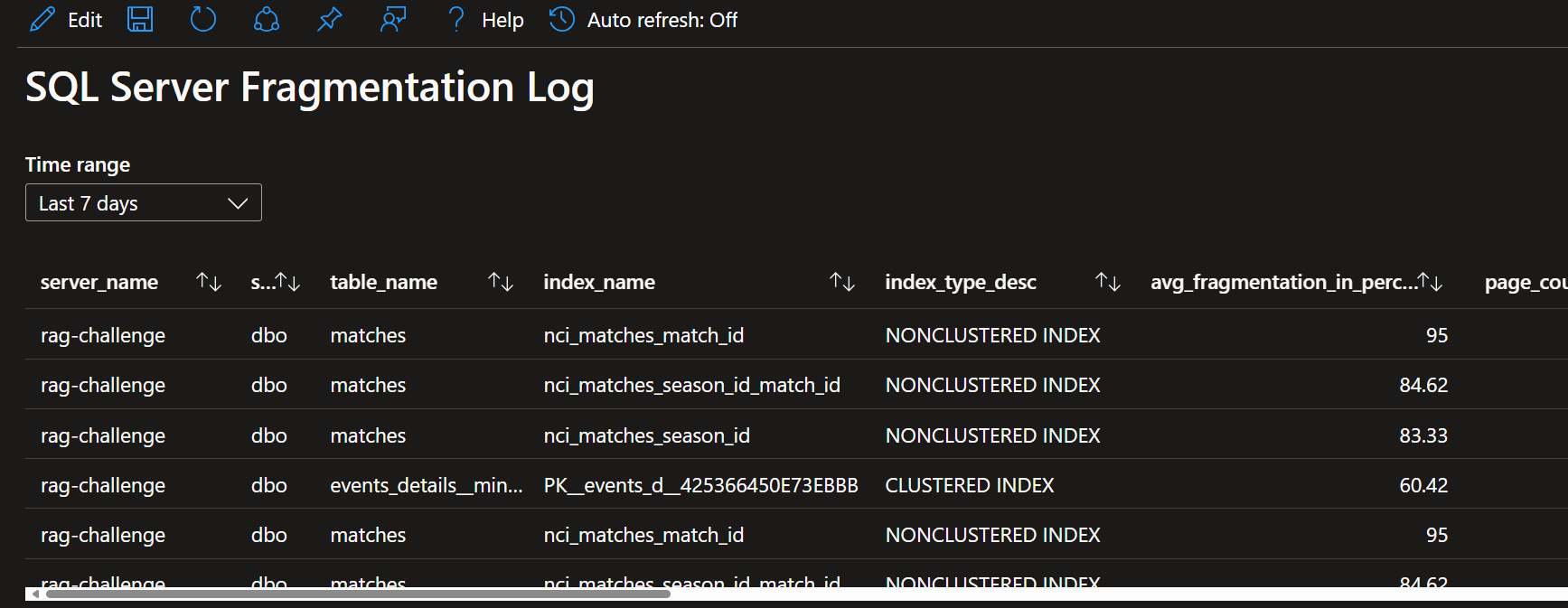
Conclusiones
En resumen, monitorear la fragmentación de índices dentro de Azure SQL Databases es esencial para mantener un rendimiento óptimo, especialmente en entornos PaaS caracterizados por cargas de trabajo dinámicas. Al aprovechar las Data Collection Rules (DCR) y los Data Collection Endpoints (DCE) de Azure, los administradores pueden recopilar y analizar eficientemente las métricas de fragmentación, integrándolas sin problemas con Azure Log Analytics para mejorar la visibilidad y las capacidades de Monitorización.
El enfoque descrito en este artículo no solo facilita la automatización de la recopilación de datos, sino que también cierra la brecha entre la administración de SQL Server y la gestión de Azure. Al emplear el Kusto Query Language (KQL) para consultar los datos recopilados, los usuarios pueden obtener valiosos conocimientos sobre las tendencias de fragmentación, permitiendo intervenciones oportunas para mitigar la degradación del rendimiento.
Implementar esta solución requiere una atención cuidadosa a la configuración de recursos, permisos y prácticas de manejo de datos para garantizar que el Monitorización sea efectivo y seguro. Seguir las mejores prácticas destacadas a lo largo del artículo permitirá a las organizaciones optimizar el rendimiento de sus bases de datos Azure SQL mientras mantienen una estrategia de Monitorización eficiente y receptiva.
Con las herramientas y configuraciones adecuadas, los administradores de Azure y los DBAs de SQL Server pueden gestionar colaborativamente los datos de fragmentación, asegurando que las aplicaciones funcionen de manera óptima en los entornos impulsados por datos de hoy en día.